




In contemporary software architecture, the rising popularity of distributed systems means establishing distinctive identifiers is crucial to preventing conflicts among nodes. Snowflake ID, created by Twitter (now X), stands out as one of the widely embraced algorithms for generating unique IDs.
This article describes what Snowflake ID is, how it works, what its advantages are and compares it to Universally Unique Identifiers (UUID) used for information in computer systems. Let’s start by describing the ID generation process.
ID generation process
Small traffic scenarios
In a small traffic scenario, engineers can utilize a simple system to get just one point where an ID is generated:
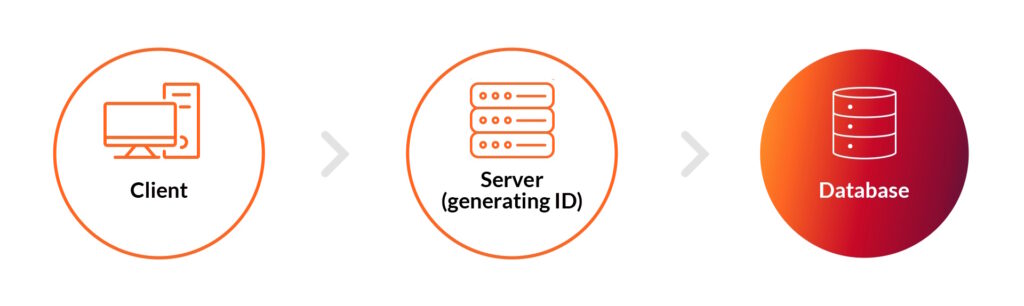
A simple system that generates IDs by iterating typically involves the use of a counter variable that is incremented each time a new ID is generated:
Initialization: A system initializes a counter variable, typically set to an initial value (e.g., 1 or 0, depending on the preference), which serves as the base for generating IDs.
ID Generation: When a new ID is requested, the system retrieves the current value of the counter and uses it as the ID. After generating the ID, the system increments the counter by one to prepare for the next ID generation.
Iteration: The system continues this process for subsequent ID requests, incrementing the counter each time to ensure that each new ID is unique and sequentially ordered.
Large traffic scenario
In more complex systems, with a more extensive data load and many clients taking to multiple servers’ base in numerous data centers, IDs are generated in many places:
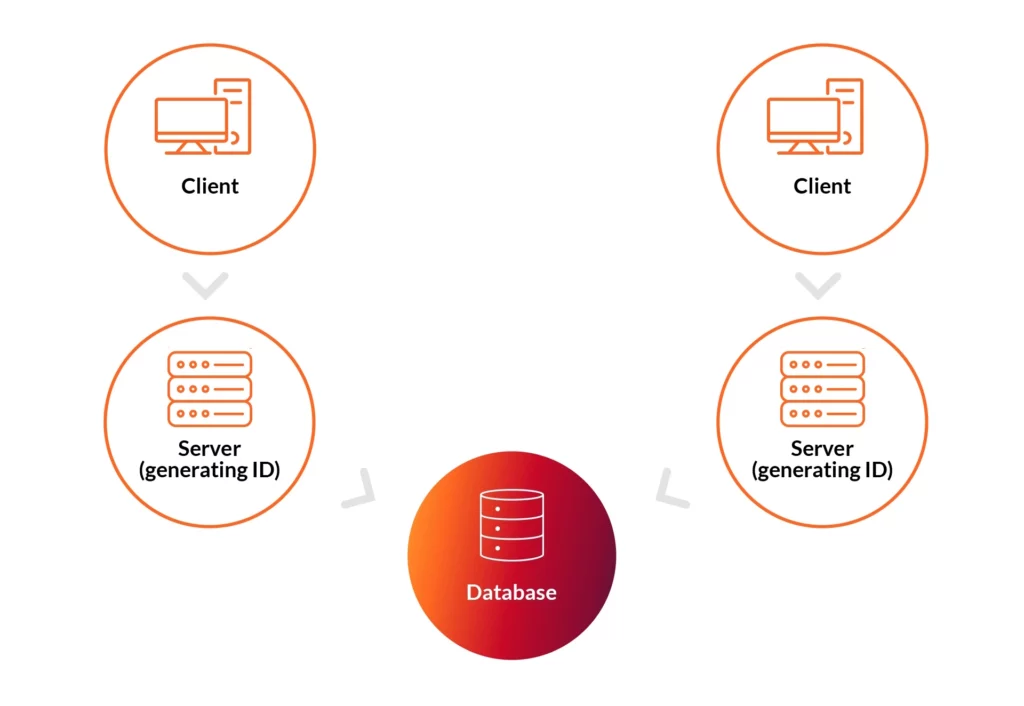
As seen in the diagram above, there are a few places generating IDs simultaneously. If you decide to proceed with the solution from a simple system and create an ID by iterating its value, you may encounter a problem where few services generate the same ID. Such an option is not acceptable.
How to overcome the problem of a unique ID?
You can use a UUID even in a highly distributed system with millions of IDs generated every minute or even second, as they are designed to be unique identifiers that are extremely unlikely to be duplicated, as after generating 1 billion UUIDs every second for the next 100 years, the probability of creating just one duplicate would be about 50%. One form of a unique identifier is known as a Snowflake ID.
What is a Snowflake ID?
Snowflake IDs are a type of identifier often used in distributed systems and databases to create unique, time-ordered IDs. The format, created by Twitter (now X) and used for the IDs of tweets, was later adopted by social media site Instagram and social platform Discord. These IDs are typically made up of multiple components, including a timestamp, a unique identifier of the generating node or process and a sequence number.

Each section presented in the graphic as explained in System Design Interview – An Insider’s Guidebook by Alex Xu:
- Sign bit: 1 bit. It will always be 0. This is reserved for future uses. It can potentially be used to distinguish between signed and unsigned numbers.
- Timestamp: 41 bits. Milliseconds since the epoch or custom epoch. We use Twitter (X) snowflake default epoch 1288834974657, equivalent to Nov 04, 2010, 01:42:54 UTC.
- Datacenter ID: 5 bits, which gives us 2 ^ 5 = 32 datacenters.
- Machine ID: 5 bits, which gives us 2 ^ 5 = 32 machines per datacenter.
- Sequence number: 12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond
What are the advantages of Snowflake ID?
The Snowflake ID has several important uses. Let’s take a look at the most crucial ones that you should be aware of:
Uniqueness: Ensuring that each generated ID is unique, even in a distributed environment, it is crucial for various operations, including data synchronization, transaction management and data consistency.
Sortability: Sorting and filtering data based on the order of creation, as a Snowflake ID typically includes a timestamp, so it to be sorted based on the generated time.
Distributiveness: Providing a way to generate unique IDs without requiring centralized coordination makes Snowflake IDs suitable for distributed environments, as in distributed systems, where multiple nodes or processes generate IDs independently and where a mechanism is needed to ensure that these IDs are unique across the entire system.

Differences between Snowflake ID and Unique ID (UUID)
Comparatively, a unique ID, which is also used to distinguish between different entities, might not necessarily include a sortable timestamp. While it guarantees uniqueness, it might not provide any information about the time of creation. Unique IDs are often generated using various algorithms or techniques, such as UUIDs, GUIDs (Globally Unique Identifiers), or other custom methods.
UUIDs and Snowflake IDs differ also in the number of bits each identifier occupies. UUIDs, characterized by their 128-bit length, offer an extensive range of possible unique values. On the other hand, Snowflake IDs, more concise at 64 bits, demonstrate a deliberate design choice for efficiency. This compactness directly enhances performance. Database indexes built on 64-bit integers are smaller and more efficient than those on larger 128-bit types. Smaller indexes can be cached more effectively in memory, leading substantially faster substantially faster to substantially faster read operations, queries, and table joins.
Transmitting a 64-bit value requires less bandwidth than a 128-bit one, reducing network latency and improving inter-service communication speed. This efficiency in generation, storage, and transmission makes Snowflake IDs a superior choice for systems where every bit of performance and every byte of storage is critical.
Snowflake IDs offer the advantages of both uniqueness and storability, making them well-suited for applications in distributed systems where both properties are necessary. The structured nature of a Snowflake ID facilitates easier database sharding and distribution across multiple nodes, which contributes to better scalability and performance. Unique IDs primarily focus on ensuring uniqueness but may not provide the additional benefit of being sortable based on creation. What should you use in your system? It would be wise to base your decision on the scale of your project, implementation overhead and performance requirements. There is no single best answer, but you can tailor your identifier to ensure optimal functionality based on your specific needs.
Snowflake ID and its growing importance in the era of AI
The Snowflake ID is essential for managing large AI and machine learning datasets. AI systems often need to process vast amounts of information, where the order in which the data is generated is crucial. Snowflake IDs are designed with a 64-bit structure with a high-precision timestamp, making them inherently sortable by time. This feature is significant for applications such as training models on event streams or ensuring the correct order of transactions in fraud detection algorithms. Chronologically ordering the data simplifies preprocessing and feature engineering, eliminating the need for an additional indexing column for sorting, which speeds up data retrieval and processing.
The distributed nature of Snowflake IDs complements the scalable architectures of modern AI platforms. Each identifier is guaranteed to be unique across a distributed system, eliminating the need for a central coordinating authority. This feature is crucial for large-scale data ingestion and labeling, especially when multiple nodes generate data simultaneously. These IDs’ unique and time-ordered nature is also essential for data versioning and traceability. It enables data scientists to accurately track the lineage of the datasets used for training models, which is vital for reproducibility, debugging, and maintaining model governance in complex AI workflows.
If you need any advice regarding modern software architecture, creating custom distributed systems or scaling horizontally, contact our experts using this form.
Discover our related case studies and learn how we assisted various companies in their projects:
Designing a real-time machine learning platform for a large bank
Standardizing online advertising data by migrating from Microsoft to Snowflake
Developing a data preparation layer
FAQ
What is the identity ID in Snowflake?
In Snowflake, an identity ID is a column property that automatically generates unique numeric identifiers for each new row in a table. Using the identity or autoincrement keyword ensures that every record receives a distinct, system-generated number. This approach simplifies database management by guaranteeing the uniqueness of each row, which is essential for maintaining data integrity, particularly for primary keys.
How to find Snowflake ID?
To find your Snowflake account ID, you can use the Snowsight web interface. After logging in, click your name in the upper-left corner, then navigate to the account switcher. Your account identifier will be displayed there. Alternatively, you can execute the SQL query Select Current_Account (); in a worksheet to retrieve the account locator.

About the authorSoftware Mind
Software Mind provides companies with autonomous development teams who manage software life cycles from ideation to release and beyond. For over 25 years we’ve been enriching organizations with the talent they need to boost scalability, drive dynamic growth and bring disruptive ideas to life. Our top-notch engineering teams combine ownership with leading technologies, including cloud, AI, data science and embedded software to accelerate digital transformations and boost software delivery. A culture that embraces openness, craves more and acts with respect enables our bold and passionate people to create evolutive solutions that support scale-ups, unicorns and enterprise-level companies around the world.









